

Part 3
Interpreting Correlation: Proceed with Caution
One trap that we all have fallen into is within us: Our own bias. Bias is a disproportionate weight in favor of or against an idea or thing, usually in a way that is closed-minded, prejudicial, or unfair. Within statistical analysis, bias occurs when you overestimate or underestimate the population parameter of interest. While difficult to manage, there are ways of controlling the monster that bias can be.
Once you have overcome the obstacle of picking the right sample size for your analysis, the next step is collecting an accurate sample of the population of interest. The sample is a group of individuals that represent a population. A simple random sample (SRS) is a sample of the population being analyzed, chosen at random. To take a random sample, you might use a lottery method as in “drawing from a hat” from your entire population. Or, you can use a random number generator, where you assign each individual in your population a number. You would then use a random number generator to select the numbers or individuals that you would include within your sample. While it may be a tedious process, a random sample ensures that the sample within your analysis is as closely representative of the population of interest as possible.
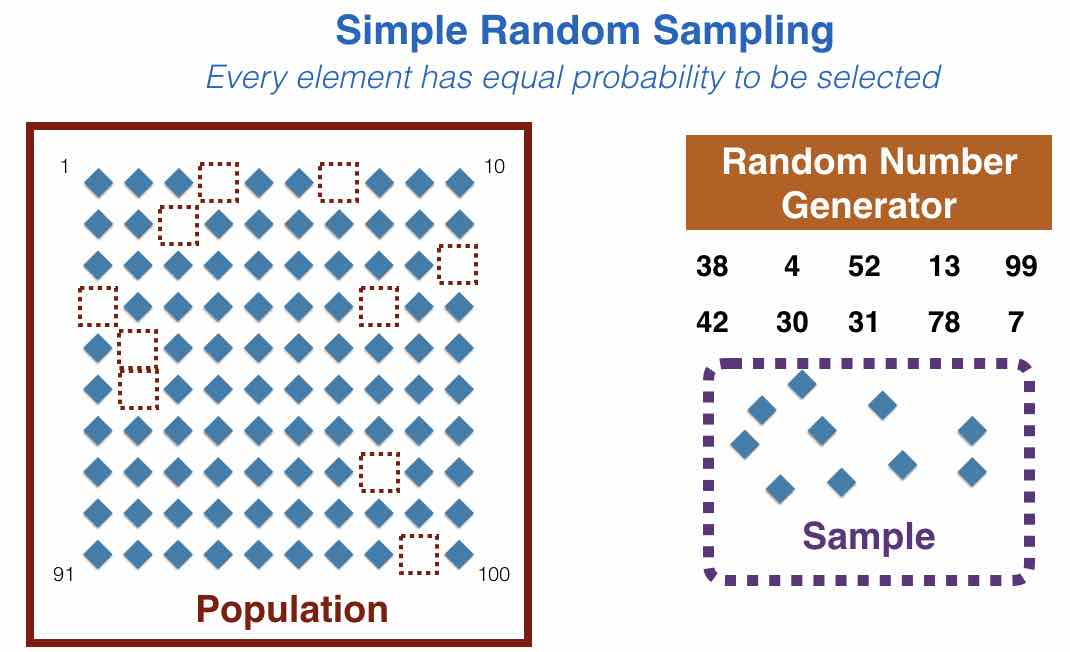
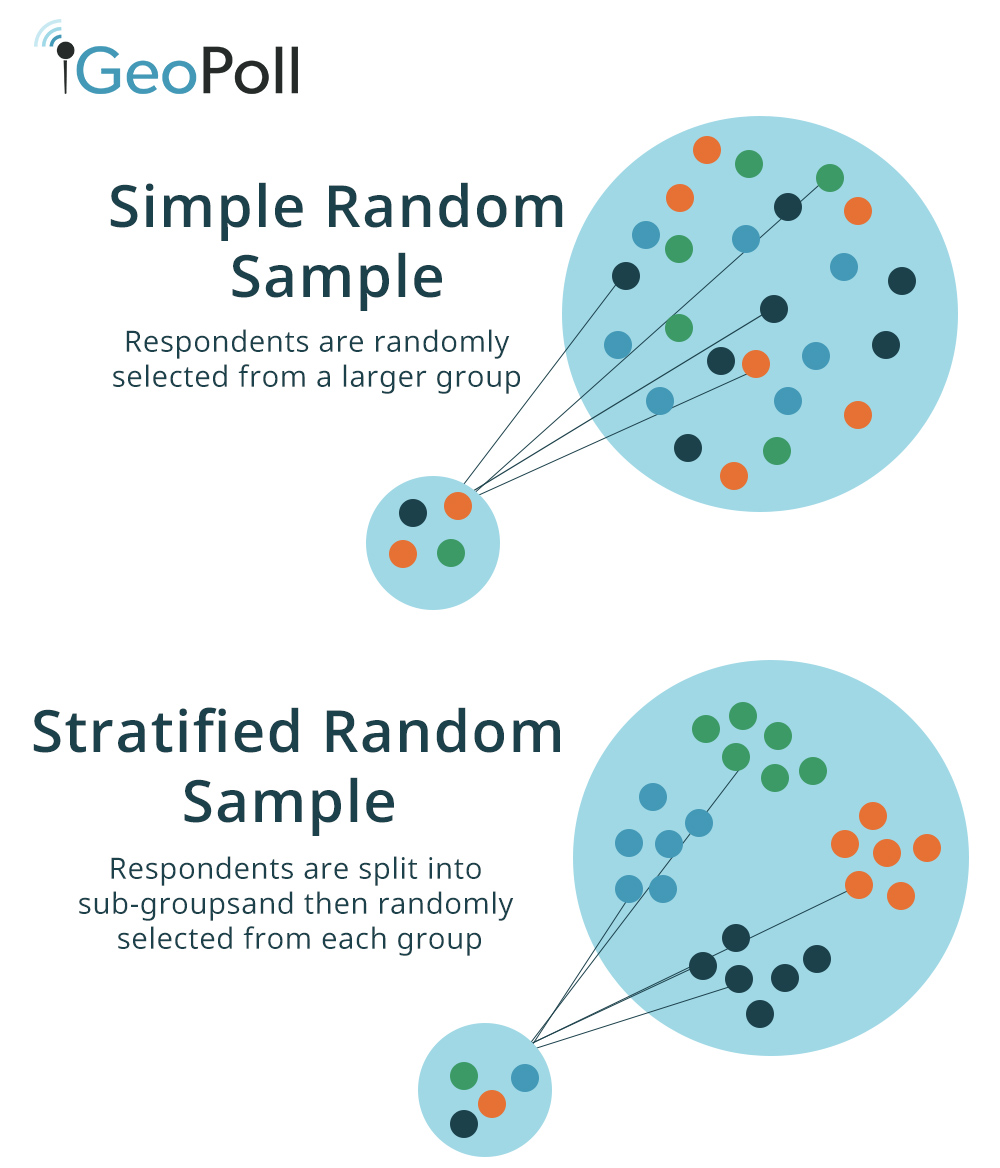
While a random sample removes bias and is the preferred method of attaining a sample, there are other methods of generating your sample. Stratified sample, cluster sample, systematic random sample, and others, all provide samples that represent the population of interest, but will include some sort of bias compared to a sample, solely based on chance. For example, a stratified random sample breaks your data into sub-groups. Within each of these subgroups, a random sample is performed to achieve X amount of individuals from each sub-group. The benefit of this method of gathering your sample data is that it ensures that all “groups” within the population are represented, compared to the chance that one group is over-represented in a SRS, as those individuals are chosen simply through chance.
Bias isn’t just found in sampling; bias within results is one of the largest beasts to conquer. Confounding variables are external factors that may affect your results. For example, if you are studying weight gain based on activity level, you have to consider that many factors will play a role such as age, gender, genetics, type of workout, and so on. Just because something seems to be the case, doesn’t mean it is the only factor causing it to happen. Simply put Correlation ≠ causation. This is one of the largest mistakes seen within analysis. It is true, NO correlation = NO causation, but this is not the case for the opposite. Just because your analysis shows there is statistical association (correlation) between variables A and B, it does not mean that variable A causes variable B to occur. Frequently, we fall into the trap of jumping to conclusions based on what the data seems to be telling us, when in reality there is no knowing for certain if that conclusion is true or not.
Thematic Stock Ideas!  Granny Shots Rebalanced Quarterly
Our Granny Shots have outperformed the S&P 500 by 95% since inception! |
American author and economist Thomas Sowell once said, “One of the first things taught in introductory statistics textbooks is that correlation is not causation. It is also one of the first things forgotten.”
In investing, this idea couldn’t be more relevant. When analyzing performance and stocks, look for reasoning, not just statistical links. Any causal explanation must be made apart from the statistics. Then we can avoid making statistics the third kind of lie.


Related Guides
-
 Series of 4~10 minutesLast updated1 year ago
Series of 4~10 minutesLast updated1 year agoCommodities 100
An introduction to commodities for novice investors.
-
 Series of 3~11 minutesLast updated1 year ago
Series of 3~11 minutesLast updated1 year agoUnderstanding Risk and Return: Hallmarks of Investing
Risk/return is so crucial to investing that it is sometimes considered the essential element of the whole craft. In this guide, we provide insights and tools to better understand risk and how to control it.
-
 Series of 7~24 minutesLast updated1 year ago
Series of 7~24 minutesLast updated1 year agoTom Lee's Seven Principles of Evidence-Based Research
It is important to be evidence-driven when making decisions in equity markets. People have acclaimed some of our team’s market calls, but if you look closely much of the time, we were just following the data.
-
Series of 3~15 minutesLast updated1 year ago
Investor Psychology 100
You may have heard this before: Many of the world’s top investors manage their portfolios well because they manage their emotions well. But what does that look like? If you want to know more about investor psychology – arguably the most critical component of the entire game -- you’ve come to the right place. Let’s dive in.
-
 Series of 8~22 minutesLast updated1 year ago
Series of 8~22 minutesLast updated1 year agoFinancial Instruments! How to use them and what are they for!
In this guide, we will talk about financial instruments. We will cover stocks, bonds, various kinds of derivatives, and more!
-
 Series of 1~6 minutesLast updated1 year ago
Series of 1~6 minutesLast updated1 year agoWhat is Ethereum?
We are launching a new guide covering Ethereum, the highlights from inception to the current state of the network!

